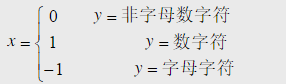题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
从STRIN单元开始有一个字符不同的字符串,串长50字节。要求将CHRT单元中的字符与字符串中字符进行比较,若字符
中不含有该字符,则置MARK单元为0;若该字符包含在字符串中则置MARK单元为0FFH,并将该字符从字符串中删除,被删除字符后面的所有字符依次向前递补,串长减1。
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
 更多“从STRIN单元开始有一个字符不同的字符串,串长50字节。要求将CHRT单元中的字符与字符串中字符进行比较,若字符”相关的问题
更多“从STRIN单元开始有一个字符不同的字符串,串长50字节。要求将CHRT单元中的字符与字符串中字符进行比较,若字符”相关的问题
第4题
第6题
STACK SEGMENT STACK
DW 32DUP()
STACK ENDS
DATA SEGMENT
BUF DB 50()
DATA ENDS
CODE SEGMENT
START PROC FAR
ASSUME CS:CODE,DS:DATA,SS:STACK
MOV AX,DATA
MOV DS,AX
LEA SI,BUF
(1)
CON:
INT 21H
MOV [SI],AL
INC SI
(2)
JNE CON
MOV AX,4C00H
INT 21H
START ENDP
CODE ENDS
END START
第7题
STACK SEGMENT STACK
DW 32 DUP()
STACK ENDS
DATA SEGMENT
BUF DB 50()
DATA ENDS
CODE SEGMENT
START PROC FAR
ASSUME CS: CODE, DS: DATA, SS: STACK
MOV AX, DATA
MOV DS, AX
LEA SI, BUF
[1]
CON:
INT 2IH
MOV [SI],AL
INC SI
[2]
JNE CON
MOV AX, 4COOH
INT 2IH
START ENDP
CODE ENDS
END START
第9题
第10题
设有一篇英文短文,每个单词之间是用空格分开的,试编写一算法,按照空格数统计短文中单词的个数。
算法分析如下:要统计单词的个数先要解决如何判别一个单词,应该从输入行的开头一个字符一个字符地去辨别。假定把一个文本行放在数组s中,那么就相当于从s[0]开始逐个检查数组元素,经过若干个空格符之后找到的第一个字母就是一个单词的开头,此时利用一个统计计数器num进行累加1运算,在此之后若连续读到的是非空格字符,则这些字符属于刚统计到的那个单词,因此不应将计数器num累加1,下一次记数应该是在读到一个或几个空格后再遇到非空格字符开始。因此,统计一个单词时不仅要满足当前所检查的这个字符是非空格,而且要满足所检查的前一个字符是空格。