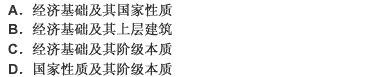题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
Spark根据RDD的依赖关系来划分Stage,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到窄依赖就断开,遇到宽依赖就将其加入当前Stage。()
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
 更多“Spark根据RDD的依赖关系来划分Stage,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到窄依赖就断开,遇到宽依赖就将其加入当前Stage。()”相关的问题
更多“Spark根据RDD的依赖关系来划分Stage,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到窄依赖就断开,遇到宽依赖就将其加入当前Stage。()”相关的问题
第1题
A.RDD具有血统机制(Lineage)
B.RDD默认存储在磁盘
C.RDD是一个只读的,可分区的分布式数据集
D.RDD是Spark对基础数据的抽象
第2题
A.[0,numPartitions]
B.[0,numPartitions-1]
C.[1,numPartitions-1]
D.[1,numPartitions]
第5题
A.Spark引进了弹性分布式数据集RDD(ResilientDistributedDataset)的抽象,容错性高
B.Spark提供的数据集操作类型不仅限于Map和Reduce,大致分为:Transformations和Actions两大类
C.Spark程序由Python语言进行编写,不支持Java语言进行的程序编写
D.Spark把中间数据放到内存中,迭代运算效率高
第9题
A.都有共振现象
B.都没共振现象
C.刚性转子有共振现象,挠性转子没有共振现象
D.刚性转子无共振现象,挠性转子有共振现象
第10题
A.操作风险一旦被识别出来后,就应该加以评估,决定哪些风险具有不可接受的性质,应该作为风险转移的目标
B.对于不能定量分析的风险,必须找出这些风险的起因以及可以采取什么样的措施
C.用来估计损失事件的频率以及严重程度的有三类方法:情景分析、主观风险评价以及根据依赖关系对风险进行估计
D.AB说法都正确