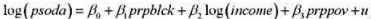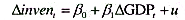题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。(i)从加速数模型中求出OLS残差,并用回归
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。(i)从加速数模型中求出OLS残差,并用回归
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。
(i)从加速数模型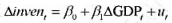 中求出OLS残差,并用
中求出OLS残差,并用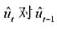 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
(ii)用PW估计这个加速数模型,并将β1的估计值与OLS估计值进行比较。你为什么预期它们很相似?
 答案
答案
查看答案