

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在例4.4中,我们针对一个大学样本,估计了一个联系校园犯罪与学生注册人数的模型。由于很多学校在
1992年都没有报告其校园犯罪数据,所以我们所使用的样本并不是美国大学的一个随机样本。你认为大学没有报告校园犯罪可被视为外生的样本选择吗?请解释。
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
 更多“在例4.4中,我们针对一个大学样本,估计了一个联系校园犯罪与学生注册人数的模型。由于很多学校在”相关的问题
更多“在例4.4中,我们针对一个大学样本,估计了一个联系校园犯罪与学生注册人数的模型。由于很多学校在”相关的问题
第1题
响。帕普克还使用了一个容许每个城市都有其时间趋势的模型:
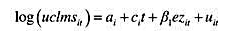
其中,αi和ci都是非观测效应,这样就可以考虑城市之间更多的异质性。
(i)证明:如果对上述方程取差分便得到
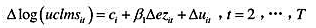
注意在此差分方程中包含一个固定效应ci。
(ii)用固定效应法估计差分方程。β1的估计值是什么?它和教材例13.8中的估计值有很大差别吗?企业园区的作用仍是统计显著的吗?
(iii)在第(ii)部分的估计中添加全部年度虚拟变量,β1的估计值有何变化?
第2题
第3题
某企业有3000名职工,该企业想估计职工们上下班在路途上的平均时间。以置信度为99%的置信区间进行估计,并使估计处在真正平均值附近1分钟的误差范围之内。一个先前抽取的小样本给出的标准差为4.3分钟。试问应抽取多大的样本?
第4题
利用GPA2.RAW中有关4137名大学生的数据, 用OLS估计了如下方程:

其中,colgpa以四分制度量,hsperc是在高中班上名次的百分位数(比方说,hsperc=5,就意味着位于班上前5%之列),而sat是在学生能力测验中数学和语言的综合成绩。
(i)为什么hsperc的系数为负也讲得通?
(ii)当hsperc=20和sat=1050吋,大学GPA的预测值是多少?
(iii)假设两个在高中班上具有同样百分位数的高中毕业生A和B,但A学生的SAT分数要高出140分(在样本中相当于一倍的标准差),那么,预计这两个学生的大学GPA相差多少?这个差距大吗?
(iv)保持hsperc不变,SAT的分数相差多少,才能导致预测的colgpa相差0.50或四分制的半分?评论你的结论。
第5题
50户,分析人员希望以95%的置信度对这个成数作出估计,并使估计值处在真正成数附近0.05范围内,在一个以前抽取的样本中,有28%的家庭看过该广告,试问应抽取多大的样本?
第6题
第7题
(i)用虚拟变量demwins来代替教材(10.23)中的demvote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果demwins>0.5,你就可以预测民主党会获胜;否则,共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健:检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。!统计量有什么明显的变化吗?
第10题
本题利用SLEEP75.RAW中的数据。我们要分析的方程为:
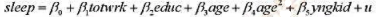
(i)分别针对男性和女性单独估计这个方程,并按照通常形式报告结论。这两个估计方程有什么明显差异吗?
(ii)对男性和女性睡眠方程中的参数是否相等计算邹至庄检验。使用增加male和交互项male totwrk,.male的检验形式,并使用全部观测。该检验相关的df等于多少?在5%的显著性水平上,你应该拒绝这个虚拟假设吗?
(iii)现在,容许男性与女性存在不同截距,判定所有涉及male的交互项是不是联合显著的?
(iV)给定第(ii)部分和第(iii)部分中的结论,你最后将使用什么样的模型?
第11题
估计值处在真值附近1分钟的误差范围之内,一个先前抽样的小样本给出的标准差为4.8分钟,试问应抽取多大样本?



















